How Much Language Do Robots Really Need?
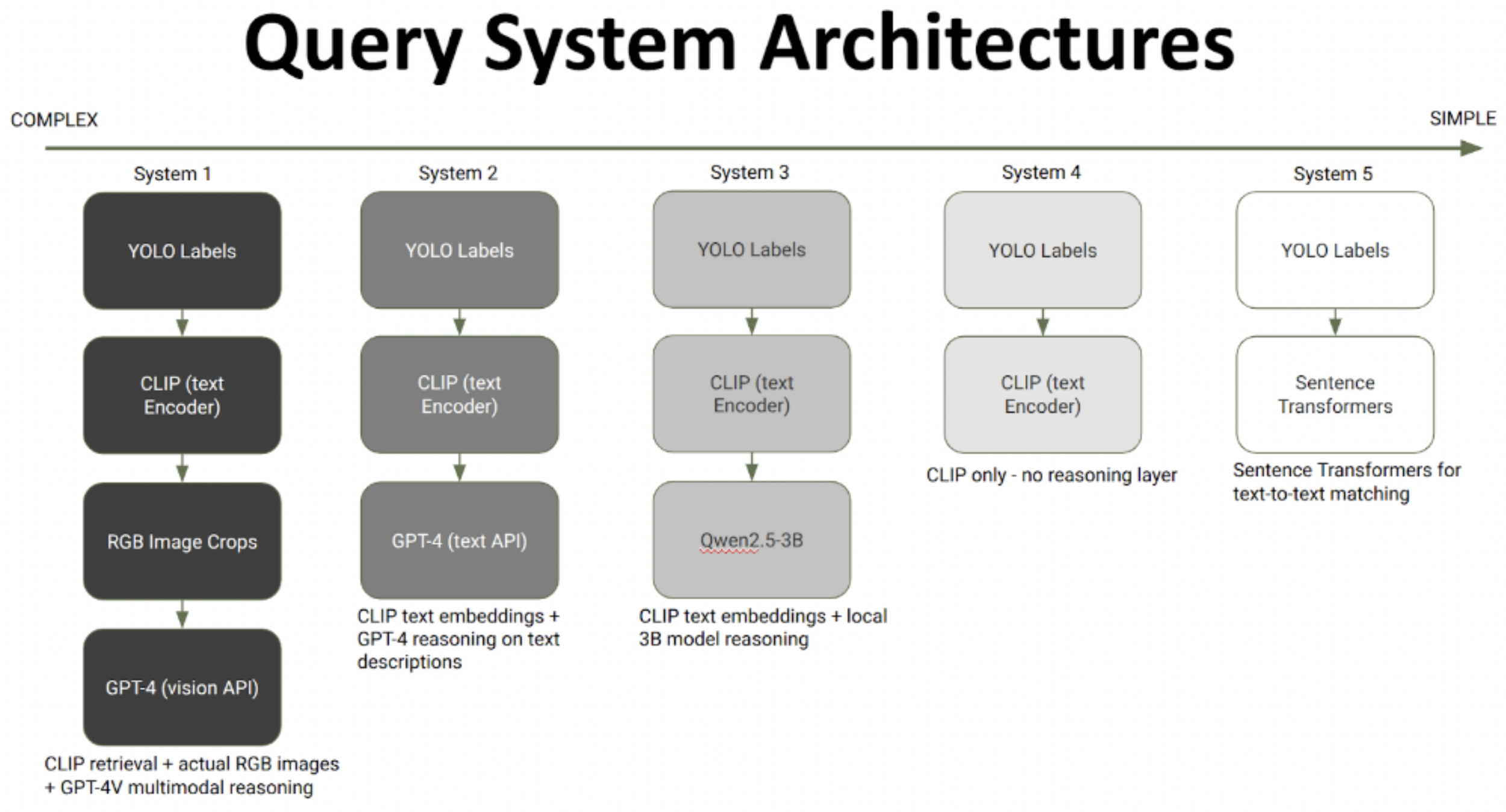
Many “language-enabled” robot navigation systems rely on cloud APIs, which breaks deployment under cost, bandwidth, and reliability constraints. This project asked a practical question: what is the minimum language stack a robot needs for useful open-vocabulary semantics when you target edge compute.
We reworked a ConceptGraphs-style pipeline to support online semantics and multi-view robustness, including embedding fusion when observations match an existing object, and whole-frame captioning so the model can use context and relations rather than isolated crops.
My core contribution was representation-driven debugging: I identified duplicate-object ambiguity as a dominant failure mode and implemented “local neighborhood signatures,” a lightweight geometry-grounded relational fingerprint to disambiguate objects in language queries.
Keywords: semantic navigation, scene graphs, VLM systems, edge robotics